Notice
Recent Posts
Recent Comments
Link
목록DQN (2)
하루 하루
 펭귄브로의 3분 딥러닝 파이토치맛_11일차
펭귄브로의 3분 딥러닝 파이토치맛_11일차
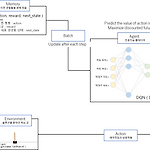
DQN ( Deep Q-Network ) 정해진 '환경(CartPole-v0)'에서 '에이전트'가 무작위로 '행동'하면서 행동에 대한 '보상'을 학습해 무작위 행동을 줄여가면서 정확도로 높여간다. 위의 그림에서 Memory는 다음과 같은 정보를 저장한다. ( state , action, reward, next_state ) 현재 상태 : state 현재 상태에서 한 행동 : action 행동에 대한 보상 : reward 행동으로 인해 새로 생성된 상태 : next_state memory 기억하기 위해서 만들어 놓은 queue 인데, 딥러닝이 모델들이 연속적인 경험을 학습할 때 초반의 경험에 치중해서 학습하기 때문에 최적의 행동 패턴을 찾기 어렵고, 새로운 경험이 전 경험에 겹쳐 쓰며 쉽게 잊어버리는 문제..
IT/Artificial intelligence
2020. 4. 27. 14:58