목록인공신경망 (4)
하루 하루
1. 선형회귀분석 주어진 데이터를 가장 잘 설명하는 직선을 찾는것 - simple linear regression : 독립변수가 하나인 경우 - multivariate linear regression : 독립변수가 여러개 인 경우 단순선형회귀분석을 한다는 의미는 y 와 x라는 데이터가 주어졌을 때, y = wx +b 라는 직선의 방정식에서 데이터를 가장 잘 표현하는 w와 b를 찾는다는 것과 동일합니다. 2. 평균제곱오차 주어진 x를 w와 b를 사용해 계산한 예측값 이 실제 값과 유사해야 의미가 있습니다. 따라서, 여러 실제값과 예측값의 차이를 계산하는 방법들이 존재하고, 평균 제곱오차는 그 중에서도 많이 사용되는 방법입니다. 예측값 y ̂ 에서 y 를 빼 차이를 구하고 더합니다. 이 때, 차이가 -인 경..
 펭귄브로의 3분 딥러닝 파이토치맛 리뷰
펭귄브로의 3분 딥러닝 파이토치맛 리뷰
http://www.kyobobook.co.kr/product/detailViewKor.laf?ejkGb=KOR&mallGb=KOR&barcode=9791162242278&orderClick=LAG&Kc= 펭귄브로의 3분 딥러닝 파이토치맛 이 책은 파이토치로 인공지능을 구현하는 방법을 알려줍니... www.kyobobook.co.kr 펭귄브로의 3분 딥러닝 파이토치맛은 컴퓨터 공학 책에서 선방을 하고 있는 한빛미디어의 딥러닝 책으로 딥러닝을 학습하는 사람들 사이에서는 입문으로 꽤 유명한 책이다. 나 또한 한 매체를 통해서 이 책을 추천받고 학습을 시작하게 되었다. 해당 책을 충분히 학습하는 데 걸린 시간은 11일정도로 적당한 시간이 소용된다. 펭귄브로의 3분 딥러닝 파이토치맛에서는 ANN, DNN, CN..
 펭귄브로의 3분 딥러닝 파이토치맛_11일차
펭귄브로의 3분 딥러닝 파이토치맛_11일차
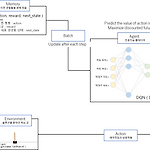
DQN ( Deep Q-Network ) 정해진 '환경(CartPole-v0)'에서 '에이전트'가 무작위로 '행동'하면서 행동에 대한 '보상'을 학습해 무작위 행동을 줄여가면서 정확도로 높여간다. 위의 그림에서 Memory는 다음과 같은 정보를 저장한다. ( state , action, reward, next_state ) 현재 상태 : state 현재 상태에서 한 행동 : action 행동에 대한 보상 : reward 행동으로 인해 새로 생성된 상태 : next_state memory 기억하기 위해서 만들어 놓은 queue 인데, 딥러닝이 모델들이 연속적인 경험을 학습할 때 초반의 경험에 치중해서 학습하기 때문에 최적의 행동 패턴을 찾기 어렵고, 새로운 경험이 전 경험에 겹쳐 쓰며 쉽게 잊어버리는 문제..